A Pyramid Approach to AWS Data Analytics
A Pyramid Approach to AWS Data Analytics
Overview
Nowadays we are producing data every second. According to Domo, “Data never sleeps.” There are 2.5 quintillion bytes of data created each day; however, these values are changing rapidly day by day. I would like to emphasise it is more exponential growth than linear that brings a new challenge and new business strategies in the tech world, where the largest organizations will be engaged in finding an analytics data solution.
In my previous blog I explained how to collect and transform data located in different AWS accounts and regions. Often, however, the enterprise company has data everywhere, not only in the cloud. One of the most common questions that I get from customers is:
Which AWS services fit well with my requirements to improve my experience with data analytics? So here I would like to show you the data model represented in a Pyramid that may be useful and provide the results you’re seeking. I would like to call it the AWS pyramid data model as it focuses only on AWS services. AWS offers a comprehensive set of services dealing with this situation to obtain, store, and analyze data of almost all types of scales and formats. The pyramid illustrates the hierarchical relationship between data and systems. Each layer represents a different workflow of the development process.
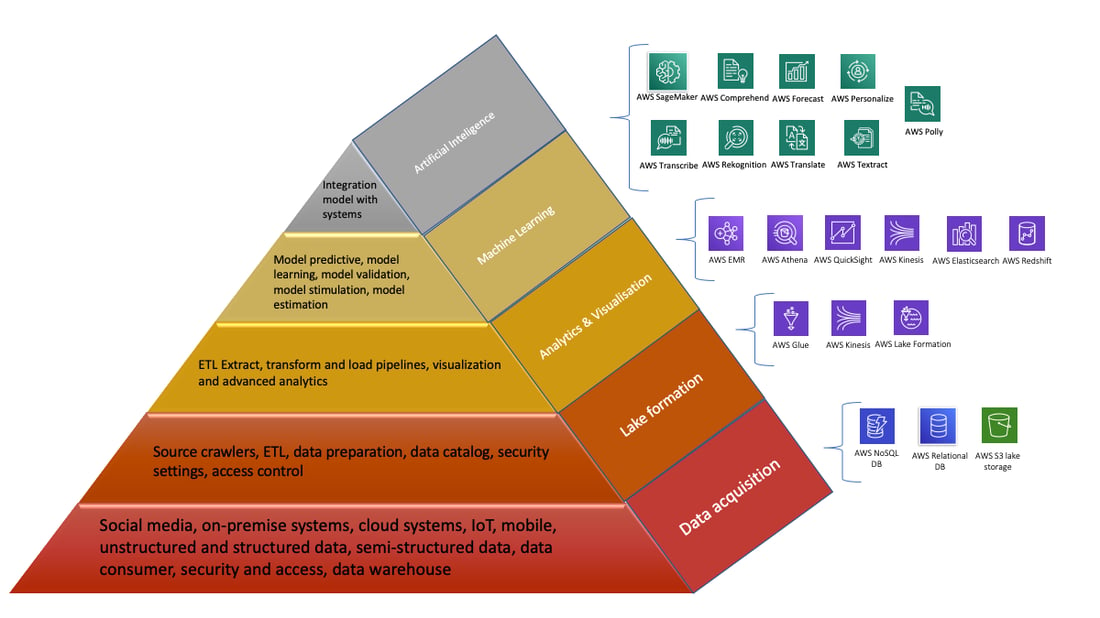
Let’s examine every layer one by one starting at the bottom of the pyramid.
#1. Collect data from the data producer
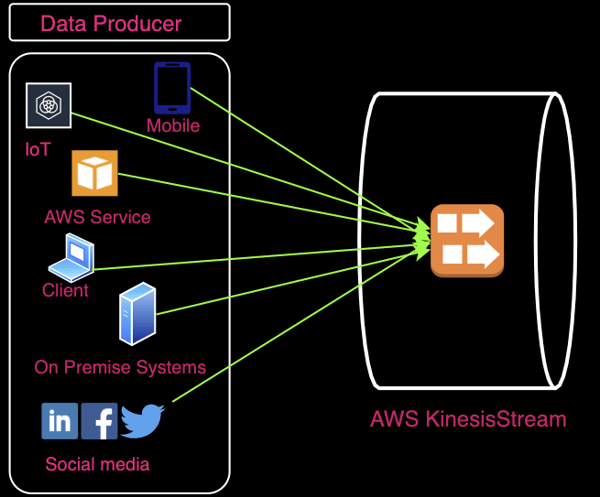
The data can be collected from information that we share on social media, applications that you keep in your datacenter, applications that you keep in the cloud, from your device, Internet of Things (IoT), financial transactions, website events, application events, database events, etc. Every cloud provider has different strategies on how to collect and analyze the data. Let me show you how to collect data on AWS.
In general terms, data can be ingested as a stream or in batches. For example, let’s look at the streaming case using Amazon Kinesis Stream. It ingests data from streaming data producers in any format or scale, then the data can be collected by installing a Kinesis agent (AWS API, or API written by you) and the capability of data ingestion depends on how many shards you create. Depending on how much as data you have, you can dynamically increase the number of shards.
#2. Lake formation (data storage)
We are living in the era of Big Data, and it has become challenging to manage the vast amounts of heterogeneous data in your own datacenter as that is both labour -and cost- intensive. Many enterprise companies want to move their data to the cloud, but they are struggling to find a good, secure and cost effective solution. In AWS, there are many alternatives for storing your data in any format. For structured data, the best option is a traditional relational database, whereas noSQL databases are preferred for storing data like logs, text, images and video. Amazon s3 buckets are recommended for static files, allowing you no limit on the quantity of objects; for backup and archive you can use AWS backup.
#3. Analytics and visualizations
Data represents one of the most valuable assets for any company. Therefore it is instrumental to understand what data analysis might bring, as this analysis may influence strategic decision making. It can enable more effective and efficient work management, discover customer needs, and understand problems facing an organization. Most of the cloud providers are investing in analytics to help customers automate the process of analyzing their data in a secure way and save some costs. However most of the services are still not mature. In AWS there are a lot of services related to analytics. I have selected some of them where these services can be used based on customer needs.
AWS Glue is a Serverless ETL AWS Service, so you can focus only on organizing, cleaning, validating and formatting your data. You can build your workflow custom pipeline involving all the activities that you need to process your data. You could have multiple components in series or parallel running in the pipeline and monitor the status of each element. Some of the important components in data pipeline are:
- Crawler allows you to connect to s3 buckets and extract data from your specific folder, then create a metadata table in a data catalog, and easily store into partitions. The crawler can also classify or identify various types of data based on the format like json, csv, grok, xml, and custom formats.
- Trigger allows you to trigger a specific activity at a specific time.
- Job allows you to transform and load data into your favorite formats; you can choose to transform the data using Spark or Python.
Amazon Athena is a serverless service that allows you to analyze a variety of data types like unstructured, semi-structured and structured data using SQL. You can create complex queries for your dataset to attain the results you’re after. Data can be located in the s3 bucket or other connections like CloudWatch, Redshift, DynamoDB, MySQL, etc. To extract data from some locations, a connection must be established, which may be performed in different ways:
- Athena uses Amazon Glue data catalog to store metadata to connect with data stored in s3 bucket.
- Athena uses a Lambda Function to connect with data stored to other services listed below.
You can also use Amazon Redshift, a managed service data warehouse, which allows you to analyze structured data. Amazon Redshift also extracts the data from different sources using JDBC and ODBC. (As opposed to Athena, which is managed by AWS so you don’t have to worry about computation.) Redshift must be managed by you: the more data you have to analyze, the more compute nodes you need, so you can increase compute resources based on your needs. Amazon Redshift allows you to query data on s3 buckets but it is very expensive. I suggest you use Athena in this case; however Redshift is the best service to use if you want to have massive parallel processing, better performance, and scale.
Amazon EMR is also a managed service in AWS, helping you to extract, transform and load data, and allowing you to analyze Big Data using Spark or Hadoop.
Amazon Kinesis Analytics is used for real time streaming analytics, allowing you to process data using SQL so you can run queries continuously.
AWS Lake Formation is another option. We all are concerned about data protection. You might wonder: Is my data encrypted? Are the right access controls applied? Who can access my data? Do I have activity monitoring in place in case something happens? Lake Formation is the right service to help you build a secure data lake, allowing you to manage and maintain data flows, storage, and access control in a secure way.
Amazon Elasticsearch Service is suitable for operational analytics for all types of data, including logs, metrics, application, web, database, infrastructure, etc. This service is integrated with Kibana, allowing you to create a dashboard and have a good visualization of the data that helps to perform various kinds of exploration. If you also want to have in place data visualisation with line graphs, charts, lines, numbers, maps etc. AWS has launched a service for this called, Amazon Quicksight. This service allows you to create custom, strategic analytics, operational, or informational dashboards.
-1.png?width=1000&name=image%20(1)-1.png)
#4. Predictive analytics and machine learning (ML)
In the modern era of the digital economy, machine learning use cases are abundant, although most current systems are not mature enough. However, many enterprises have found a high potential in cross industries like healthcare, finance, pharmaceuticals, energy, etc. Machine learning uses a combination of systems and algorithms to make predictions or decisions with minimal human intervention based on the data and automated repetitive learning. In simple terms, a machine learning system has the ability to learn from the data in input to get the results you wish. Amazon SageMaker is one of the most powerful machine learning services launched by AWS. Without worrying much about the underlying technology, you can focus on building, training and deploying a machine learning model. It provides you Jupyter Notebook based on the Python language. The workflow is very simple: you can get the input data from s3 bucket, and then start working on this data, creating a model validation, stimulation, and in the end deploy to get the analysis you desire. Sagemaker Ground Truth allows you to build training datasets for machine learning. It labels your content located in an s3 bucket working with human labelers.
#5 Artificial intelligence (AI)
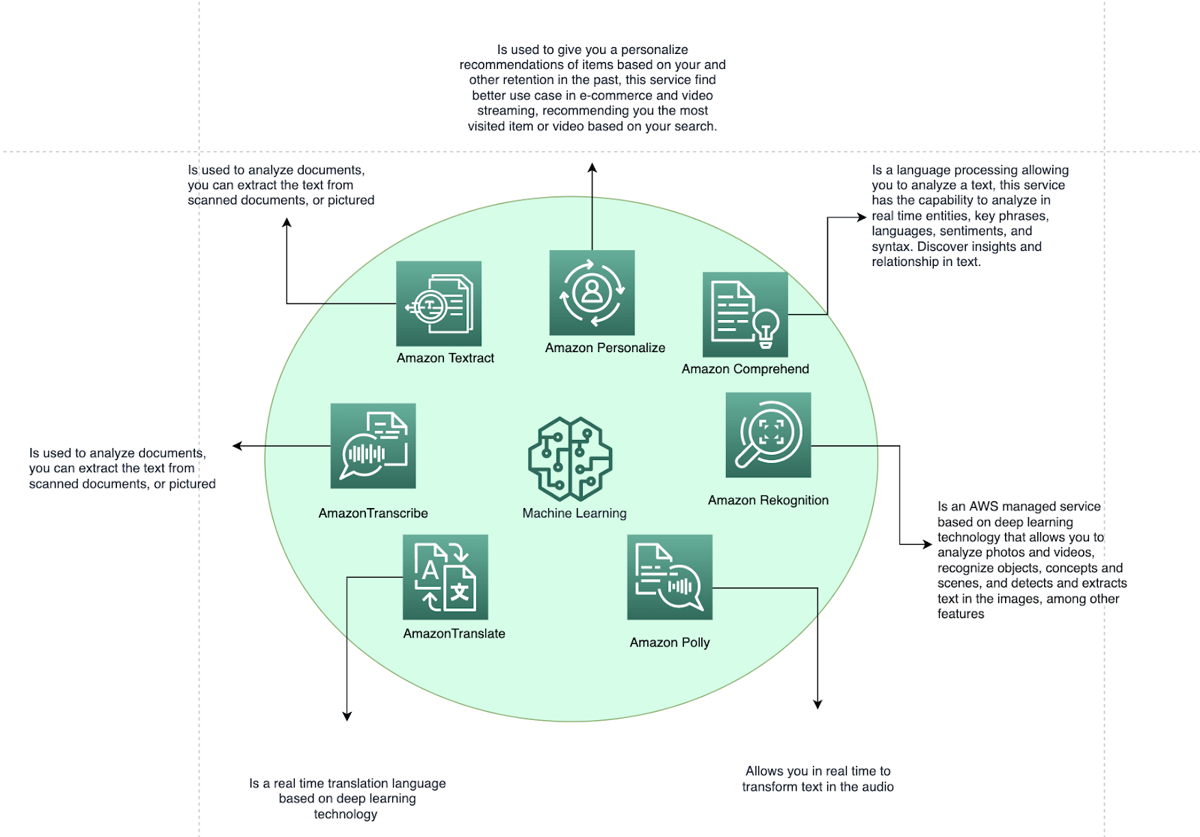
AI is at the top of the pyramid. This is probably the biggest futuristic development so far. It has become more popular today due to increasing data volumes, advanced algorithms, improvement of computer power, and storage. AI is progressing rapidly with human-like characteristics. As humans, we are amazing at being able to transform and drive our life, but also, we want to understand how AI can be integrated within the human experience. AI gets a consistent prediction to interact with a human using their natural languages. AWS offers a variety of services, and all of them are based on deep learning technology, such as vision, speech, text, audio and video analysis, chat bots, personalization, and forecast. You can build an application and integrate them together. For example, in one of my previous blogs I outlined how to transform text-to-speech. It is so easy to integrate those services. You can integrate as many services as you need. The most common capability of those services is to imitate intelligent human behaviour. Sometimes there is confusion about the differences between AI and ML. All machine learning in AWS is around Sagemaker. It allows machines to learn from themselves. AI, on the other hand, is able to carry out tasks similar to humans.
Conclusion
Having said all this, there are many ways to analyze your data to any format and scale. A variety of services allow you to collect, transform and categorize data and make it available for machine learning. Artificial intelligence has the capability to perform tasks smartly or imitate human behaviours like understanding language, text analysis, object recognition, video and image processing. The pyramid shows the fact that data engineering constitutes the bulk part of a data science project; ML/AI only becomes viable when the fundamentals are in place.
.png?width=1000&name=image%20(2).png)
https://www.mobiquity.com/insights/a-pyramid-approach-to-aws-data-analytics


Comentarios
Publicar un comentario