Building Serverless Data Lake Pipeline on AWS
Building Serverless Data Lake Pipeline on AWS
The reason of writing this post is to share my thinking with the world, to get feedback about my prototype, vision and, at the same time, to share experiences that may be of interest to data engineer practitioners, and other people.
General Data Lake Pipeline
What I’d like to do is to start with what a modern data lake pipeline looks like on AWS.


Generate
The first thing is generation, generating data sources. The typical ways to generate data sources in traditional application is done by transaction legacy system, ERP system, web logs, more and more like capturing information about consumers actually hitting the website, sensor networks feeding data into data pipeline.
Collection
The next part is collection side and you might see services like polling services running on EC2, going out to enterprise system to poll data from file systems or databases. Modern system might use technology like AWS Firehose to poll real time data. And you might also see AWS snowball which is used to transfer petabyte-scale data.
Store
On storage side, this is a very traditional piece. S3 figures a large storage of data and as you see later in this story it figures large ETL processes as well. You would see AWS RDS and customers write their own database on EC2.
ETL
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy for customers to prepare and load their data for analytics. You might use services like Lambda, S3, Cloudwatch to assist Glue crawler and job execution. There will be discussion about ETL in this article.
Analyse
You might see service like Athena which acts as a query engine against your data. You might see AWS EMR a lot of users run these services like spark processes on top of EMR. Some people might run Redshift & Redshift Spectrum while some people might run Kinesis to deal with real time data.
Virtualise Report
lastly we get the end consumer of data pipeline. You might see business users to use data in their dashboard. Business analysts who are doing things like tableau to do SQL queries as well. So there are variety applications, variety virtualisation tools end users can use.
What is the challenge
We have setup the data lake cloud pipeline and they are serverless and they looks very modern and mature. You may ask what the challenges with that?
The challenges associate using these tools with ETL stage is the volume of data they are dealing with. Some users have seen the situations where their data growth or data requirement or storage requirement have grown from a linear function to an exponential function. They are talking about how many years it takes their data to double. That has been driven by things like increasing time resolution of data, increasing sources of data.
Another things is about disparate data. You might get data coming from a general ecosystem not just from agency internal applications. So you get a community of systems trying to fit data into a single data lake.
You may see a large volume of existing data from legacy systems or from any other different applications, all generating data with different format within different times. The challenge of ETL job is to simply them to a unified way.
As a consequence, ETL stage will become a very large part in your data lake pipeline. Many organisations create many complicated scripts in spark, sql, or event bash shell to help proceed ETL process. And what we really want to be from the data is the analyst & consumer rewarding part.


What does AWS Glue try to solve is the downsize the ETL stage for organisations and systems. It is probably the tool you want to use in terms of most of ETL requirements.
What is Glue
What makes Glue so powerful. The first thing is Glue can automatically discover your data and build catalog of data, so it scans your data and put its catalog in a compatible meta data schema which can be used by Athena, Redshift etc.
Once it generates the catalog Glue makes it searchable by Athena, EMR, Redshift. They can leverage the catalog and query the data directly from S3. There is no need to load the data into a database. You can run the query against the data in place and the data catalog is the theory behind.
The other thing Glue does is to generate the ETL code for you. It generates clean logic, enrich logic, mapping logic for you. The code is adaptable which means it uses Python or Scala extension to query/transform the data. You can pull the code and run them in your choice of environment.
More importantly, Glue runs all the jobs serverless which is a very powerful feature on deploying data lake on AWS. When you run them in serverless, the jobs like OS compatible, installation, setup, infrastructure disappear which means these jobs are running on AWS cloud platform.
Lastly, Glue has the ability to schedule and trigger your jobs on your choice. You can define a schedule on a regular basis or on demand. You can also setup complex dependency chain.
How does Glue ETL work
Four Steps
Let’s go back to our theory, how do I interact with my data? The typical is four steps. In practice, many organisations have multiple iterations goes on. For now, we just describe it as four steps to complete this sequently.

Crawl
Crawling is actually a process to discover what schema is in your data. It is a simply a matter of pointing Glue at the data in s3 bucket or database running on RDS for example, telling you to find out what this schema is behind this. Glue uses crawl to discover that schema and publish the meta data on its catalog.
Map
Mapping is a step to take your source/discovered schema to your target schema. As a ETL designer, you might have some schema in your mind to map to. So you are going from source schema to a target schema. And the map step can be as simple as renaming a few fields and doing type conversion, or much complex task like restructuring your data, doing things such as relationalising your data which isn’t relationalised by its nature.
Edit and explore
Once you’ve actually done the mapping, you can run query tools directly against it to discover more structures about your data. And you can iterate this process, build a chains of ETL processes to reach your target state.
Schedule
Lastly, you can schedule these jobs. Once you’ve done with the on demand experimentation type of the process. You are ready to deploy your things on production then you can schedule these on a regular basis.
How do I discover your data?
Let me go through the steps to discover your data one by one. I will highlight some theory behind so you prepare when we get into the demo.
Glue Data Category: Crawler
As we mentioned, crawler automatically discover your data. One of the key element that it has a whole of libraries to build up classifiers. For example, if you have decade old data format that was invented by someone long since retired and it was designed by human readability and not so much for automatic processing, you can actually write customised classifier to parse that by using tools like regular expression. And you can build them with your pipeline automatically.
Crawler classifier
Classifier is the logic crawler uses to explore your data store in order to define metadata tables in AWS Glue data catalog. If the classifier recognises your data format, it generates a schema for you. Each time a crawler is executing, it may use more than one classifiers to support its work each of which returns a value known as certainty indicating its percent certain about the schema it generates. There are a few build-in classifiers you can use but you can also define your customised classifier if all build-in classifiers don’t work for your data.
Refer to https://docs.aws.amazon.com/glue/latest/dg/add-classifier.html for more information about using classifiers in your crawler.
Crawler partition
Your data may be organised in a hierarchical directory structure based on the distinct values of one or more columns. For example, you might decide to partition your application logs in Amazon S3 by date — broken down by year, month, and day. AWS Glue can use these partitions to filter data by value without making unnecessary calls to Amazon S3. This can significantly improve the performance of applications that need to read only a few partitions.
How do I build the ETL
The ETL jobs is defined as a business logic that is performed by Glue job. It links a target source table and transform the data into a target schema in a target catalog table. After completing a Glue job, you will probably have a new catalog table on Glue database as well as a target storage source like s3 bucket for storing the transformed data.
A script is generated by Glue when you start a Glue job which is to transform the data and loads it to its target storage. You can define a mapping table from source schema to your target schema in Glue job as blow. The script is generated by the column mapping table which can be in Python or Scala language with Spark extension. You can leverage all spark features to do your data transforming and reformatting and you can also setup a local environment to experiment your ETL process in a testing or dev environment.
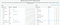

Please refer to AWS doc https://docs.aws.amazon.com/glue/latest/dg/author-job.html for more information about Glue job.
Once the job is completed, you can start querying the data through Athena.
Keep data in sync
The last thing you need to do is to keep your data in sync with data lake pipeline. Your data source will receive data all the time. The way how it works is basically to trigger Glue data pipeline whenever there is new data landing to your original data source. There are many different ways to achieve this such as defining a cron job, scheduling a cloudwatch event etc.


Sample Code
You may want to have a look what the infrastructure looks like in order to build the whole data lake pipeline. I have published a data lake project including IoC, Glue related services. You can find it from https://github.com/zhaoyi0113/datalake-severless-pipeline.
Working on data lake serverless architecture is quite different than other traditional application. Sometimes you will find it is quite hard to follow the pipeline and it is even impossible to virtualise the whole process. AWS offers us some kind of support on this part like using cloudwatch to monitor the service execution stats, set up alert message or using SNS for notifying any failures.
https://medium.com/@zhaoyi0113/building-serverless-data-lake-pipeline-on-aws-6c86883ed713

Comentarios
Publicar un comentario